Results
| Model | Train | Valid | Test |
|---|---|---|---|
| 1 | 99.81 | 93.47 | 93.25 |
| 2 | 99.95 | 93.17 | 92.73 |
| 3 | 99.97 | 92.21 | 90.75 |
| 4 | 99.84 | 93.86 | 93.81 |
| 5 | 99.68 | 93.71 | 91.58 |
| 6 | 100.00 | 94.53 | 93.09 |
| 7 | 90.85 | 88.72 | 87.62 |
| 8 | 99.91 | 94.19 | 92.95 |
Of the models including the 339-character input width and nearly-full balanced dataset, the model performing the best on the validation and testing set was the model using uppercase and lowercase letters with 256-node fully-connected layers (Model 4). On the reduced 123-character input set with the reduced balanced dataset (Model 6), the model using uppercase and lowercase letters with 256-node fully-connected layers also performed the best on both the validation and testing sets.
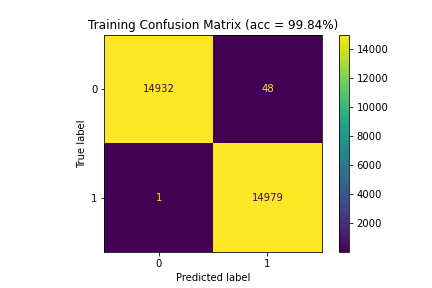
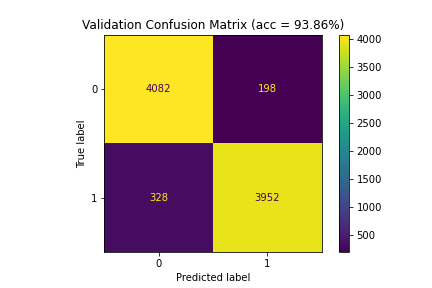
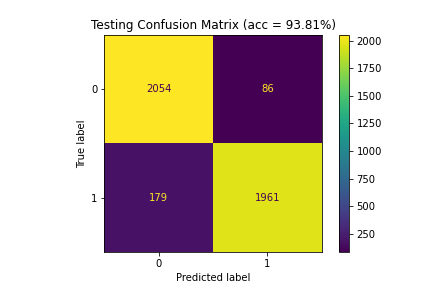
Figure 5: Confusion matrices for Model 4 (99.84%|93.86%|93.81%)
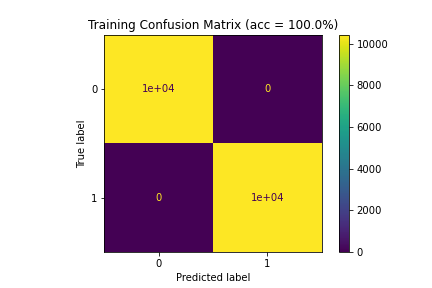
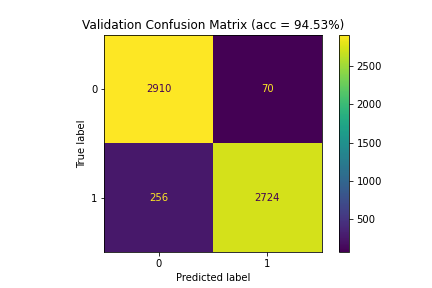
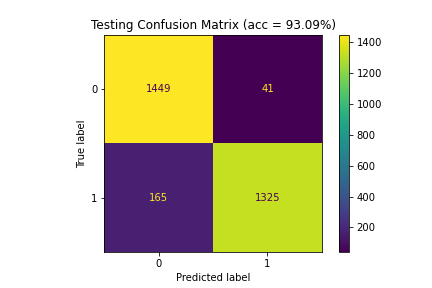
Figure 6: Confusion matrices for Model 6 (100%|94.53%|93.09%)
Conclusions and Limitations
The models could distinguish the marked differences between the real and fake titles, with consideration of capitalization potentially conferring a benefit to predictive power while incurring a relatively-small cost in computational complexity, as the number of parameters added by widening the character table has a relatively-small impact on parameter count compared to further steps in the model construction process, lending credence to its scalability and flexibility. Model structure also deserves further investigation; it is possible that a narrowed, deepened, or shortened model structure may be best, as the effects of altering other aspects of layer attributes or model structure ought to be explored. In images, the stacking of layers with smaller kernel sizes is an efficient way to detect features while cutting down on the overall number of parameters tuned. Since the convolution operation only exists in one dimension in the case of text data, we do not necessarily reap the benefit of reduced parameters with this method, but it is possible that increased classification accuracy justifies the slight increase in computational expense of a deeper network with narrower filters. Finally, considering that the real and fake data were derived from specific sources, there remains a major concern that the model may be overfitting based on detecting certain ‘signatures’ within the text that, for example, may misclassify genuine news headlines regarding a conspiracist’s-favorite topic, or may not be written in the prosaic style of Reuters; with a larger and more diverse dataset, the model can become better attuned to the underlying features within headlines, and alterations to its configuration become more meaningful.