Classification of fake news article titles using character-level convolutional neural networks
Abstract
Automated detection of spurious news and spam often rely on abstracting lexical, morphological, syntactical, or affective content from text. These models have merit in corresponding with human-observer features, but information is lost, and the features may not follow normal distributions, especially in short excerpts of text such as titles. Existing often rely on inclusion of the body text, which may or may not exist in real-world applications; since these article titles are accessible in metadata across platforms, classification of headlines has a much broader use case. We propose a method of applying character-level convolutional neural networks, a character-agnostic feature recognition system that combines the sentence-as-time-series philosophy of word2vec with a less constrained view of what information may be useful to classification, while vastly minimizing preprocessing time.
Introduction
Fake news has become pervasive within the public consciousness since the mass inter-generational adoption of multi-platform social networks such as Facebook, Twitter, and YouTube. The decentralized nature of social networks engenders the formation of echo chambers in online spaces, and growing distrust in government and mass media have not led to healthier skepticism towards all media but instead a growing trend for people to reject information that runs counter to their narrative as “fake news” while uncritically lending credibility to spurious information. Fake news may not be 100% false, but the term applies to information reported wherein a seed of truth is abstracted heavily or combined with “alternative facts” to bend and obscure the truth to fit a narrative. This rise in the transmissibility of fake news has led to the proliferation in disinformation—misinformation deliberately spread to have financial, social or political influence. In comparison to disinformation and misinformation spread through legacy media, which was largely spread by local and national state actors within or across borders, disinformation spread through social networks may have a variety of authors, from domestic and foreign governments, extremist groups, and politicians, to business figures and local or international profiteers—those who earn money from disinformation through advertising revenue, related product sales, or capital gains from favorable movements in the prices of financial instruments. In order to limit the spread of fake news, social media sites have introduced various methods of detection, from screening out websites known for misinformation, to text detection within articles and/or metadata, to advanced methods such as text detection using optical character recognition within images. These attempts are not without their flaws, however, as over-sensitivity to specific keywords, patterns, and phrases may exist.
Previous published methods of text classification of fake news articles, titles, and opinion-related spam in general include analysis of lexical, psychological, grammatical, syntactical, and morphological features, or analysis of the relative frequency or salience of words or their stemmed forms. We propose a method of spam classification that relies not on abstracted features or content but instead a language-agnostic method that takes the individual characters as input. Though applying character-based text classification is a relatively-trivial extension of the application of convolutional neural networks to categorically-structured data, it is only now become more accessible due to recent advancements in both software development and hardware being able to handle the time and memory complexity.
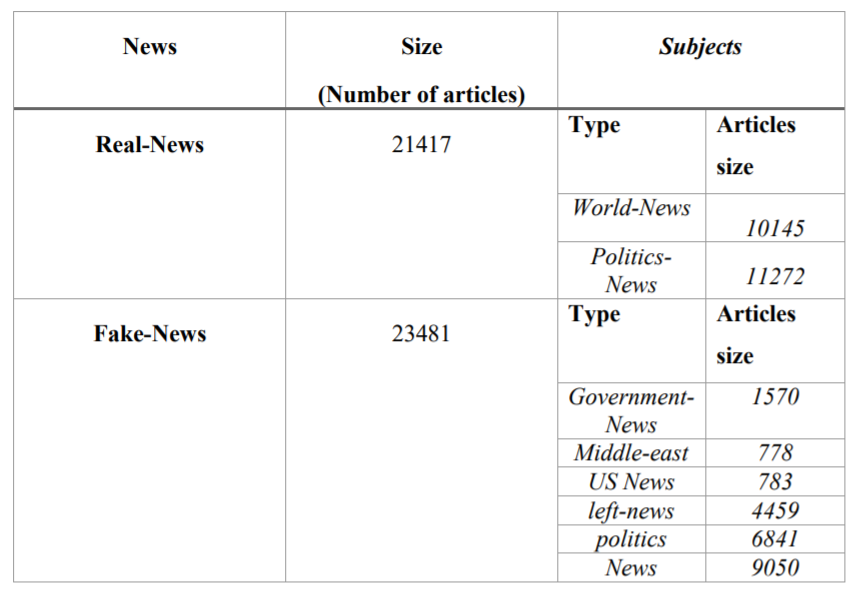
Figure 1: Breakdown of topics.
Exploratory Data Analysis
The data come from the Kaggle Fake vs. Real News dataset from Ahmed, Traore, and Saad (2017) and "Ahmed et al. (2018), which contains fake and real headlines, article bodies, topics, and dates in two class-separated csv files, with 23481 fake articles, with \(y=1\) for label, and 21417 real articles with \(y=0\) for label. All of the real articles come from Reuters, while the fake articles come from a Kaggle collection assembled from articles flagged by Politifact and Wikipedia. Because the data from the fake news sites have a more diverse underlying source than the real news, it is possible that there are reader-salient elements within the genuine article bodies that may ‘tip off’ the classifier as to what class to which the article belongs; for example “CITY, Country (Reuters) -” is the header of most Reuters body paragraphs, and “21NEWSWIRE” is in several of the fake news paragraphs.
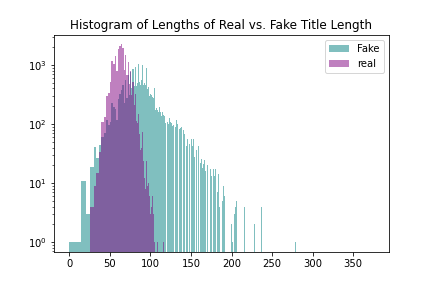
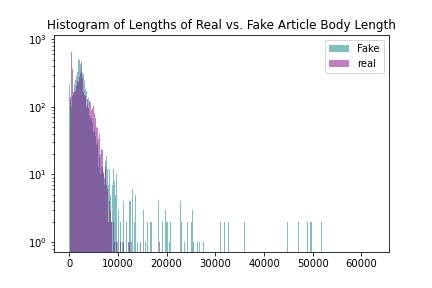
Figure 2: Histograms of real and fake titles and article texts
The real titles have more variability in length, while the distribution of fake news article body texts has a strong rightward skew. Few real article titles are shorter than 30 characters or exceed 100 characters in length, so that indicates that there may be appr/opriate boundaries within that range, so tests should be carried out with reduced data.